流程描述
使用spark 和 kafka 做数据处理。将接受的kafka种的消息。按照消息的类型,去执行不同的任务处理器。
在获取kafka 信息流的rdd中的job时 foreachjob 根据jobType对象进行传输sparkSession 对象中。
val jobs = rdd.map(x => {
// println(x)
var j = JSON.parseFull(x).get.asInstanceOf[Map[String, Any]]
var jobType = j.getOrElse(JOB_TYPE, "test").asInstanceOf[String]
var msg = j.get(JOB_MSG).get.asInstanceOf[String]
Job(jobType, msg)
})
jobs.foreach(job => {
println(job.jobType)
println(job.msg)
val ps: EtlProcess = job.jobType match {
case "oss" => new EtlProcess with OssImportProcess
case "audit" => new EtlProcess with AuditDataProcess
}
ps.process(spark, job.msg)
})
在传输过程中,rdd的算子中取foreach 任何数据都会序列化 由于sparkSession 不能被序列化,出现为null的情况
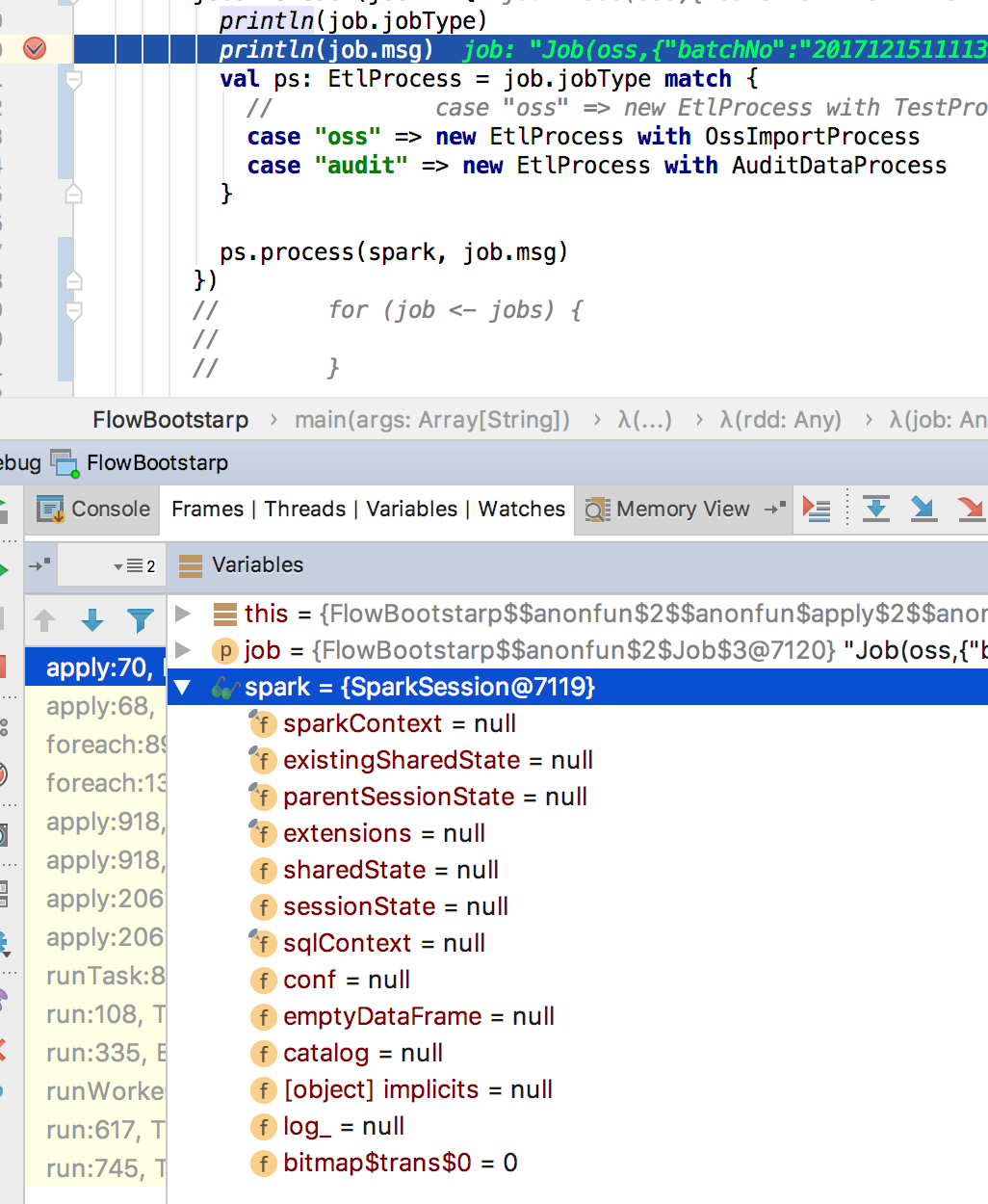
原因
查看源码,类似这种rdd的action操作,rdd会把任务分发处理 runJob 这个过程的会被序列化的。
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
解决办法
使用collect 或者 toLocalIterator 返回需要处理的数据数组,这个使用已经rdd 算完的结果了。再去foreach根本不会需要序列化
val jobs = rdd.map(x => {
// println(x)
var j = JSON.parseFull(x).get.asInstanceOf[Map[String, Any]]
var jobType = j.getOrElse(JOB_TYPE, "test").asInstanceOf[String]
var msg = j.get(JOB_MSG).get.asInstanceOf[String]
Job(jobType, msg)
}).toLocalIterator
