基本概念
机器学习是从数据中产生模型的过程。
模型的能力:
拟合:描述已有数据之间的映射关系
预测:对未知数据有预测能力(泛化 generalization)
假设函数:
用来描述两个数据之间的映射关系
损失函数:
用数学的方法衡量假设函数预测结果与真实值之间的"误差"
超参数:
需要人为确定的参数
机器学习分类:
监督学习:
分类:
决策树: decision tree
svm
回归:
线性回归: linear Regression
非线性回归: GBRT
无监督学习:
聚类: clustering
词嵌入: word embeding
问题建模:
假设函数(hypothesis function):
线性假设函数
神经网络
损失函数(cost function):
均方差(mean square error)
交叉熵(cross entropy)
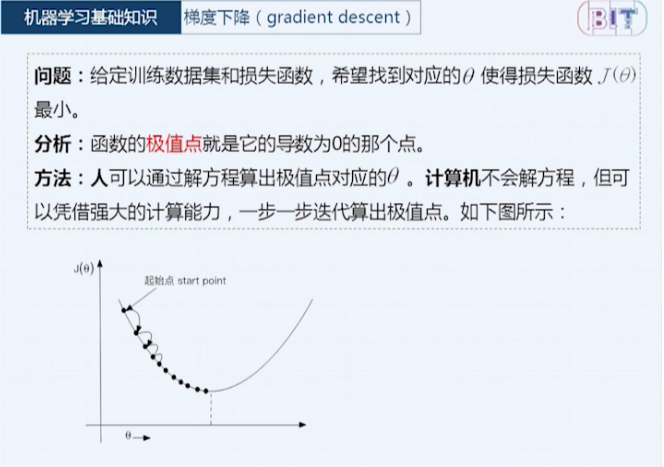
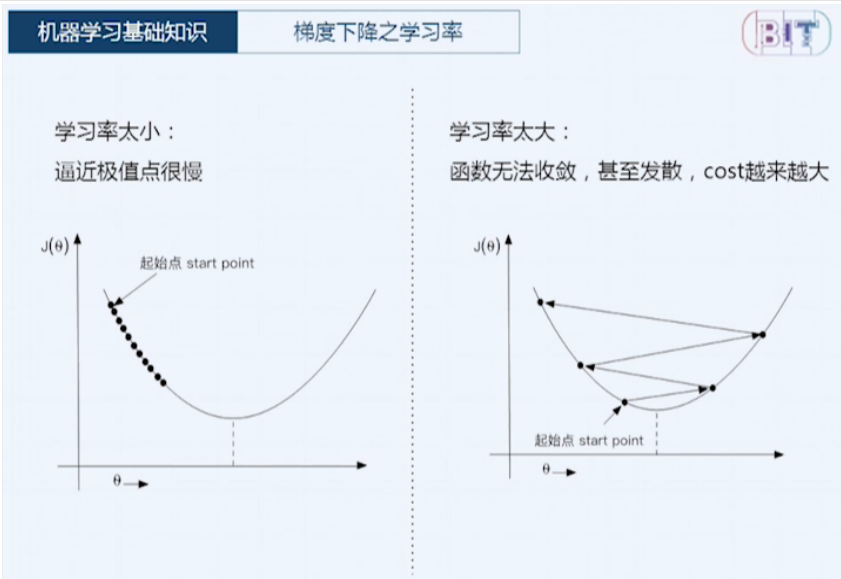
优化算法(梯度下降 gradient descent):
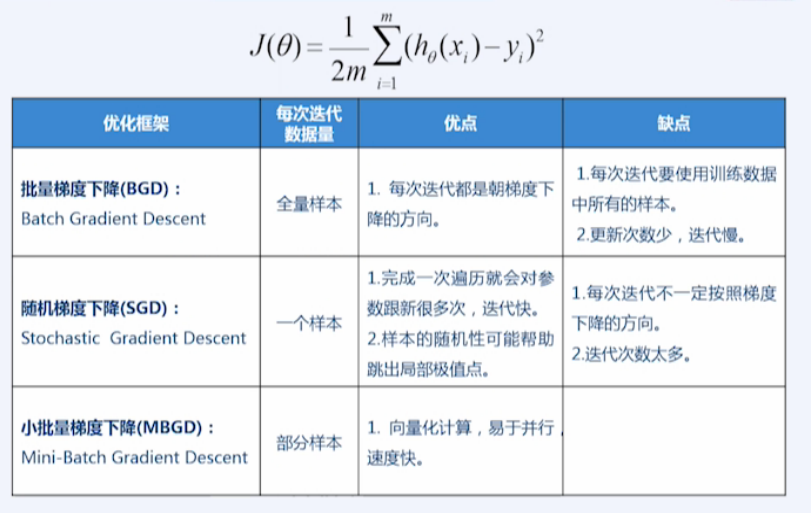
三种优化框架:
BGD
SGD
MBGD
多种优化算法:
Momentum
Adadelta
Adam
Adagrad
三种梯度下降算法
http://bit.baidu.com/course/detail/id/137.html
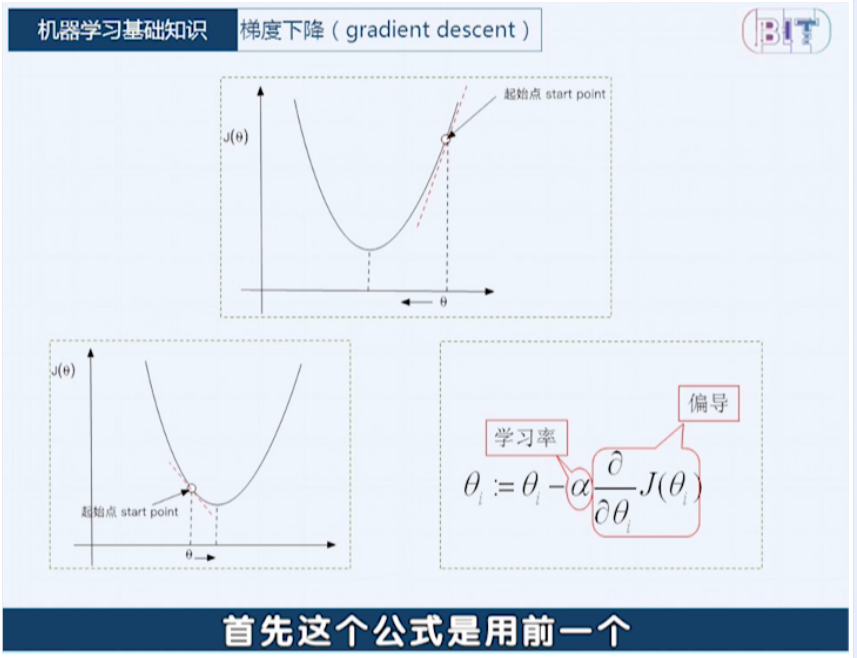
这里 a 是超参数
线性回归预测房价

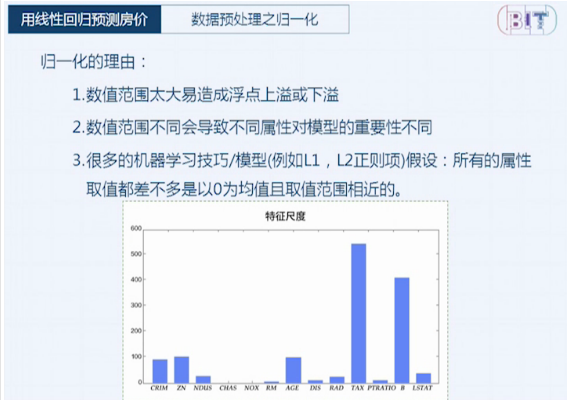
线性回归优点:
形式简单,易于建模
同时蕴含着机器学习中一些重要的基本思想
可演变成其他复杂模型
许多功能强大的非线性模型(nonlinear model)可在线性模型基础上演变而来。
可解释性好
权重可以表达各属性在预测中的重要性,因此线性模型有很好的可解释性。
术语:
监督学习(supervised learning)
非监督学习(unsupervised learning)
假设函数(hypothesis function)
均方差(mean square error)
损失函数(cost function)
梯度下降(gradient descent)
数据集操作 paddle.dataset/paddle.reader
全连接层 paddle.layer.fc()
线性激活函数 paddle.activation.Linear()
均方差损失函数 paddle.layer.mse_cost()
参数优化器 paddle.optimizer.Momentum()
梯度下降训练器 paddle.trainer.SGD()
数字识别
全连接
激活函数
卷积
池化
Softmax 回归模型
多层感知器模型
卷积神经网络模型
数据集:
MNIST 手写开源数据集(6万训练,1万测试)
重要的积木
全连接(fully connected): 每一个神经元都和上一层所有神经元相连。
激活函数(activation function)
卷积(convolution)
池化(pooling)
分类器
softmax 回归模型
多层感知机模型
卷积神经网络
全连接神经网络的缺点:
参数太多
没有利用像素之间的信息
为什么要用激活函数:
神经网络每层输出都是上层输入的线性变化。
y = Wx
无论神经网络有多少层,输出都是输入的线性组合
引入非线性激活函数,神经网络才可以逼近任意函数
y = f(Wx)
softmax 回归模型: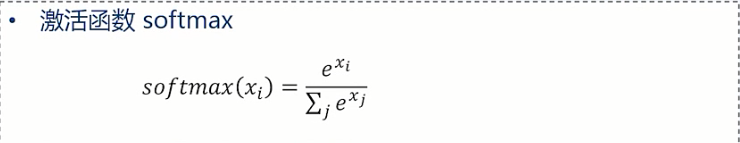
常用于神经网络输出层的多分类
对于N个类别的多分类问题,将结果向量归一化为 N 个 [0,1] 范围内的实数值
每个实数值对应一个类别的预测概率
步骤:
将输入层经过全连接得到的特征
通过softmax 激活函数进行分类输出

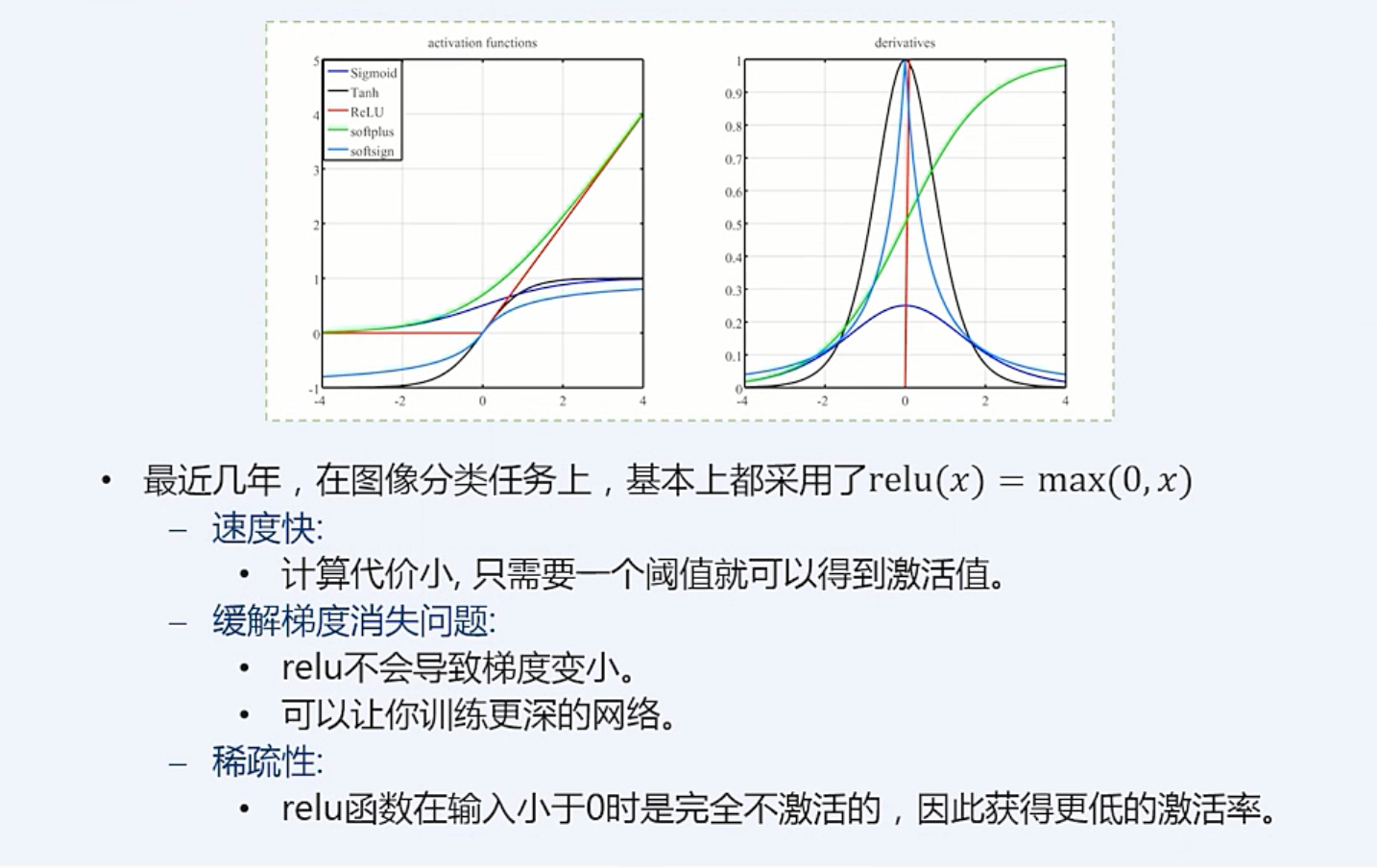
ReLu 激活函数的梯度(倒数图):
x < 0, 梯度为 0
x > 0, 梯度为 1
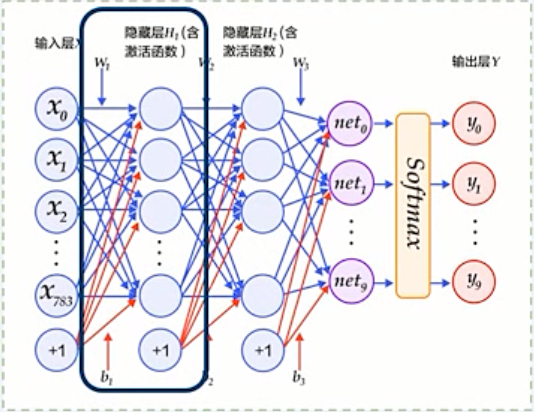
多层感知器模型
计算方法:
将输入层连续经过两个全连接隐层
经过输出层 softmax 函数进行分类
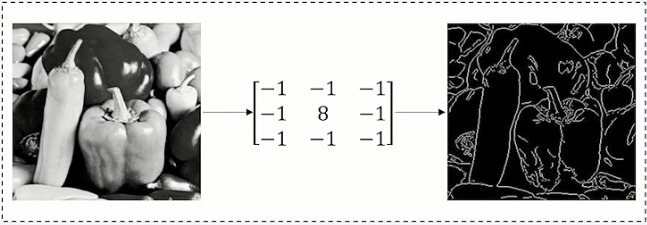
卷积(Convolution)
卷积是卷积神经网络的核心基石, 卷积操作可以提取出图像低级到高级的特征
滤波器(也称作卷积核) 与二维图像做卷积操作来提取特征
卷积操作被广泛应用于图像处理领域, 不同卷积核可以提取不同的特征,如边沿,线性,角等特征。
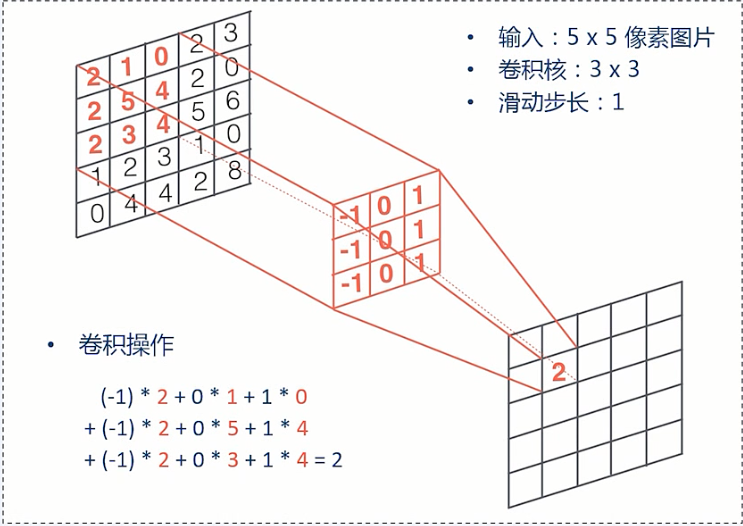
卷积核滑动到二维图像上所有位置,并在每个位置上与该像素点及其周围像素点做内积
在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征
通过卷积核,使得仅与输入神经元的一块区域连接,这块局部区域称作感受野
这种局部连接保证了学习后的过滤器能够对于局部的特征有最强的响应
卷积主要特性:
局部连接
每个神经元仅仅与输入神经元的一块区域连接, 减少很多参数
权重共享
一组连接共享同一个权重, 这样又减少了很多参数
卷积层使得需要学习的参数大大减小, 这样也有利于训练较大卷积神经网络
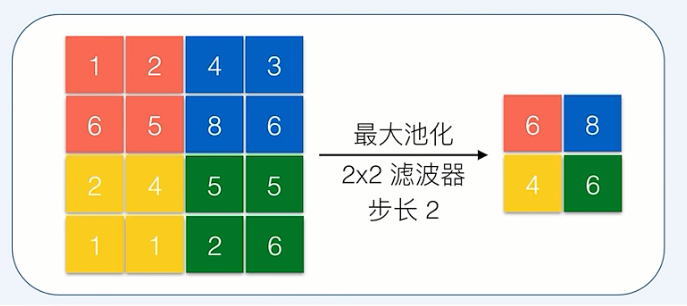
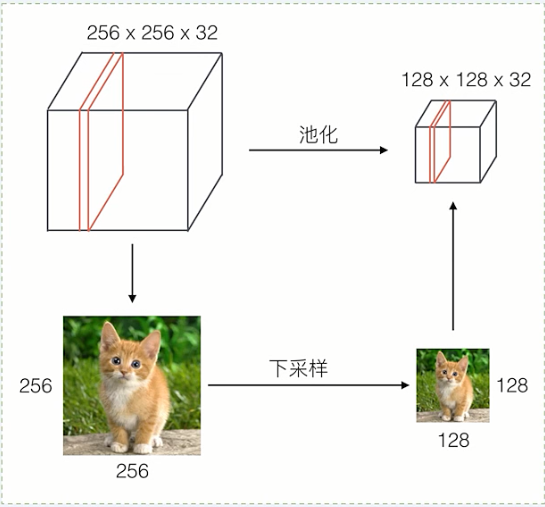
池化(polling)
池化是非线性下采样的一种形式
池化包括最大池化,平均池化
最大池化是将输入分成不同的区域,对于每个区域的数取最大值作为输出
通过减少网络的参数来减小计算量
能够在一定程度上控制过拟合
通常在卷积层的后面会加上一个池化层进行下采样
LeNet-5 卷积神经网络的演示
经过两次卷积层到池化层
经过全连接层 + Softmax 分类
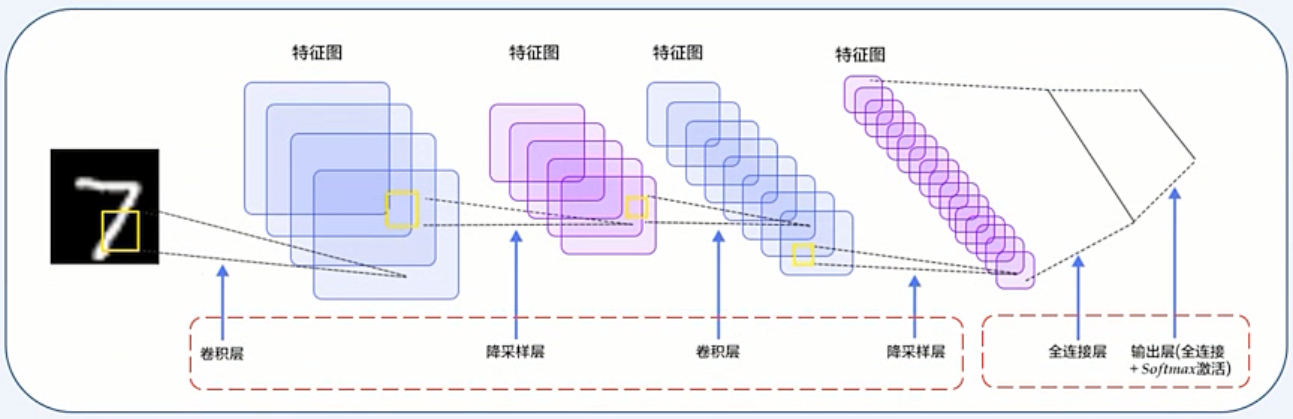
总结
全连接神经网络模型,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息
卷积神经网络利用卷积和池化,能够更好地利用图像的结构信息
卷积神经网络通过尽可能保留重要的参数, 通过去掉大量不重要的参数来达到更好的学习效果
图像分类
图像识别:
计算机对图像进行处理分析、识别、理解。

图像识别:
识别出汽车,马路
图像检测:
识别出汽车位置,进一步识别出拥堵等语意
图像分类挑战:
http://cs231n.github.io/classification/

模型概览:
AlexNet
VGG
GoogleNet
ResNet
传统方法表示
(含有大量冗余和噪声)底层特征表示 ---> (进一步整合底层特征得到)中层特征表示 ---> 分类器
传统方法特点:
多个步骤 (需要多步优化,多步优化就会造成错误的累积)
手工设计特征,通常需要多种特征进行融合
发展缓慢
常用分类器:
svm
Adaboost
卷积神经网络的方法:
底层特征 ---> 中层特征 ---> 高层(语意)特征 ---> 分类器
特点:
学习特征(不需要多个步骤,一步到位端到端的方法)
端到端
精度高
较好的迁移能力
大规模视觉挑战赛
CNN 积木回顾
卷积层
局部链接
权重共享
输入输出:(N、C、H、W)四维数据结构
N: Batch Size
C: Channel
H: Height
W: Width
全连接层
池化层
ReLu 函数
softmax
总结
特征迁移:
其他细粒度图像分类: 使用 ImageNet 模型 finetune
医疗图像识别: 使用 ImageNet 模型 finetune
使用 Oxford-flowers/ImageNet 数据进行训练
个性化推荐
背景介绍
推荐系统和搜索引擎的区别: 信息找人,而不是人找信息
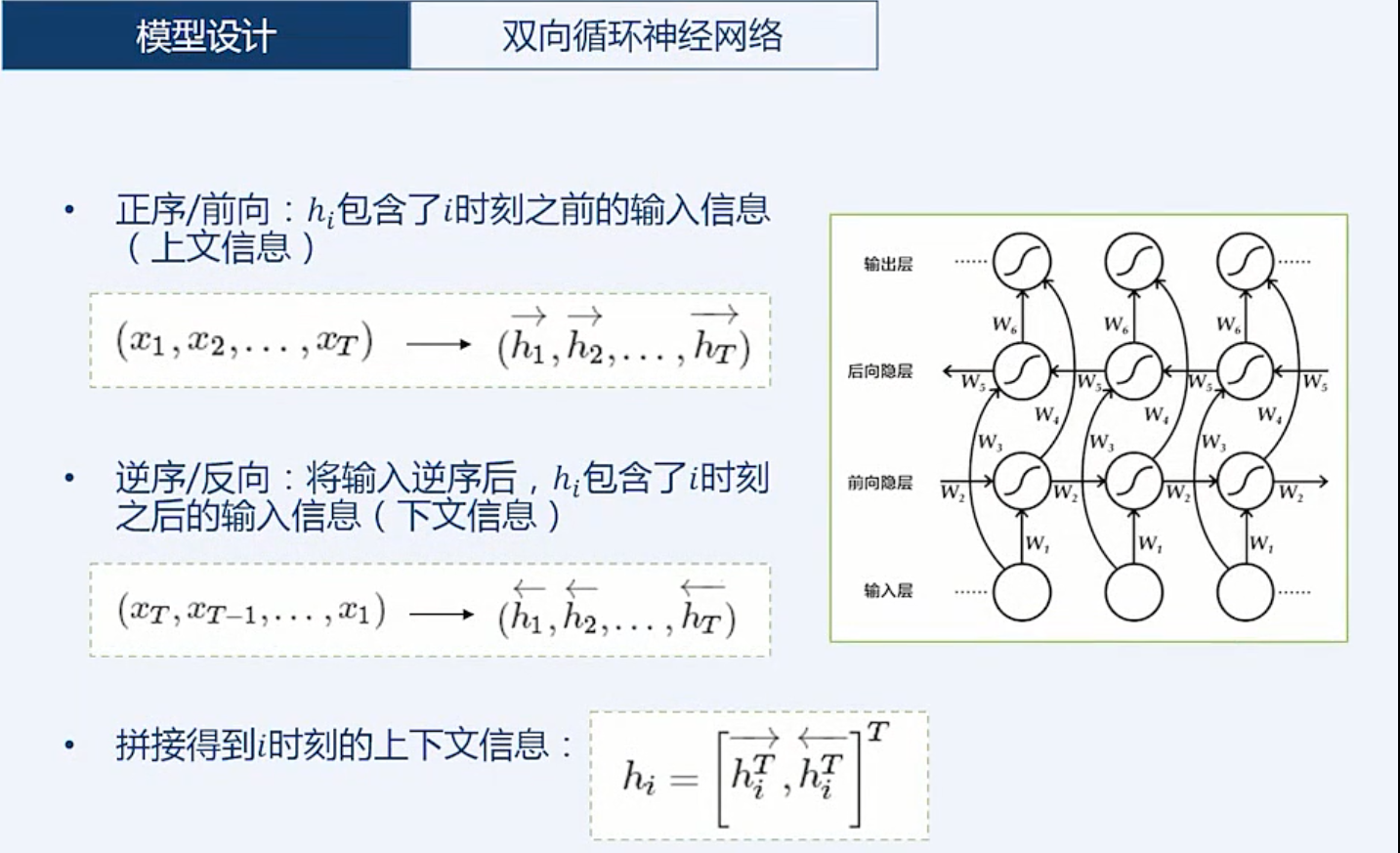
模型设计
文本卷积神经网络
LTR: Learn to Rank
文本卷积神经网络
文本输入 =》上下问词向量拼接 =》全连接卷积层 =》 池化 =》输出
LTR 基本方法
pointwise
排序可以被建模为分类、回归等模型
输入: 单个商品的特征向量
输出: query 与每个商品的相关度
优点: 简单易用
局限性: 未考虑商品与商品之间的联系
pairwise
输入: 具有偏序关系的商品对
输出: 每对商品的偏好值(1 或 -1)
listwise
输入: 某个 query 下所有商品
输出: 排好序的列表或排列
微软 刘铁岩博士 论文

数据集
MovieLens 百万数据集
6000 位用户对 4000 部电影的一百万条评分
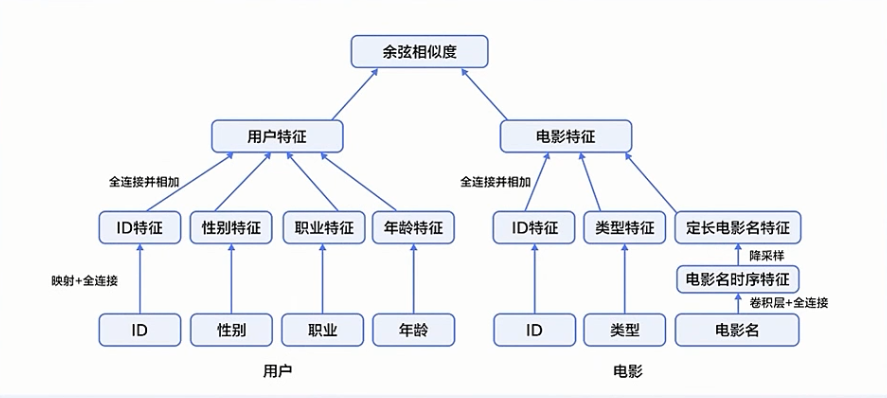
用户特征: ID、性别、 职业、年龄
电影特征: ID、类别、电影名
地址:
http://files.grouplens.org/datasets/movielens/ml-1m-README.txt
为了简化 , PaddlePaddle 对数据做了预处理
https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/dataset/movielens.py
模型结构
paddlepaddle 数据类型文档地址
http://doc.paddlepaddle.org/develop/doc/api/v2/data.html
延伸
http://files.grouplens.org/datasets/movielens/ml-latest-README.html
https://www.themoviedb.org/documentation/api
通过数据集中的电影 ID 调用 api 得到电影的海报,使用神经网络对海报进行学习。
情感分析
情感分析
意见抽取, 意见挖掘
自然语言处理任务
判断一段文本所表达的情绪状态
文本: 一句话, 一个段落,一个文档
情绪: 正面, 负面
情感分析任务
最基本的: 一段文本表达的态度是正向的还是负向
稍微复杂: 将文本表达的态度分成 1-5 个等级
情感分析应用
电影, 购物, 社交, 金融, 机器人
模型设计
情感分类
文本分类
循环神经网络RNN
LSTM
栈式双向LSTM
模型训练
RNN模型计算
Batch计算
文本情感分类(面向文本处理)
基于情感词典及规则
基于机器学习方法
有监督的机器学习
实现端到端的情感分类
文本分类
文档分类
垃圾邮件过滤

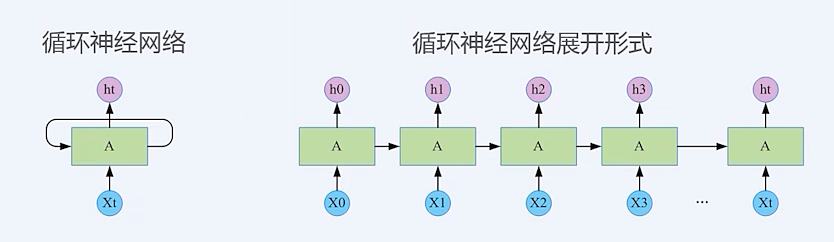
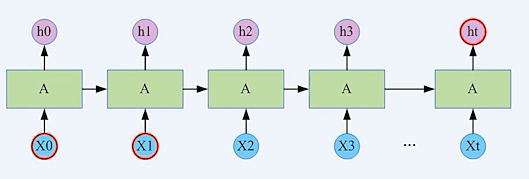
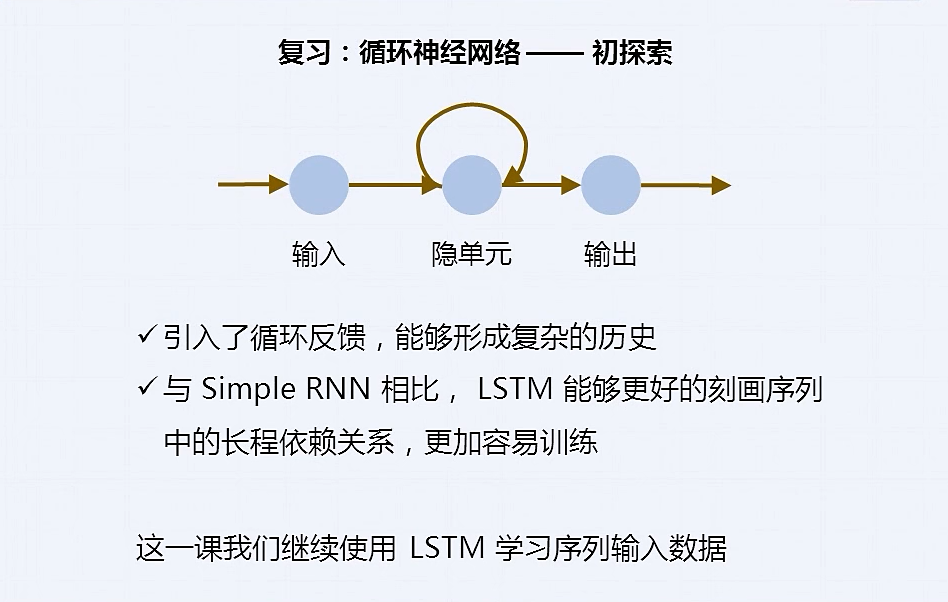
循环神经网络(Recurrent Neural Network)
上一时刻的输出作为下一时刻的输入
自然语言,典型的序列数据(词序列)
长序列
长期依赖(Long Term Dependencies)
梯度消失/梯度爆炸
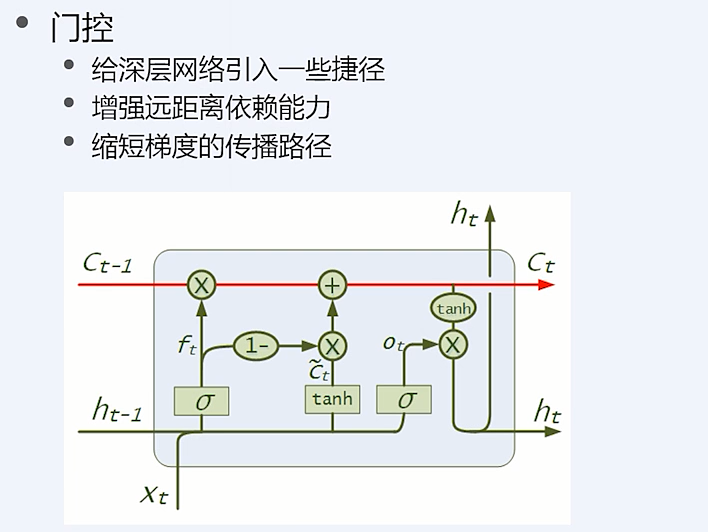
LSTM 网络
为了解决简单 RNN 网络里面的长距离依赖和梯度消失的问题, 有了 LSTM 网络
增强了处理远距离依赖问题的能力,同时缩短了梯度的传播路径
类似的设计还有门控循环神经网络单元 GRU

数据集
IMDB 情感分析数据集
分别包含25000训练样本和测试样本
标注为正面评论或负面评论
dataset/imdb.py
自动下载
读取字典、训练数据、测试数据 API
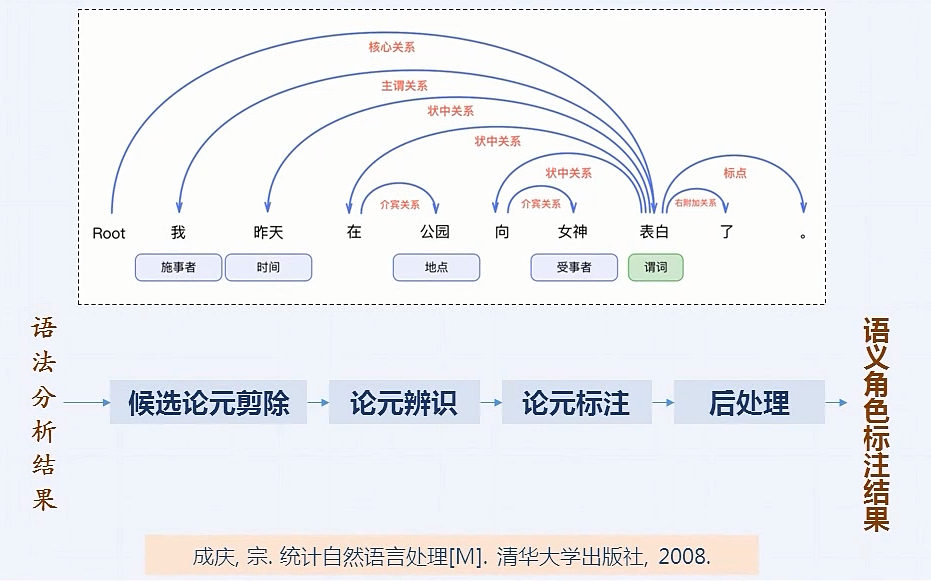
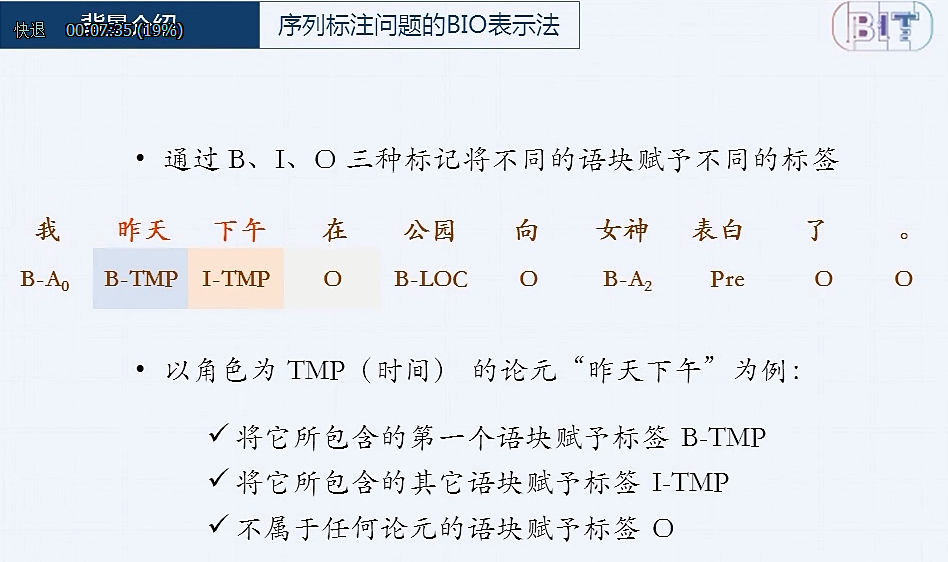
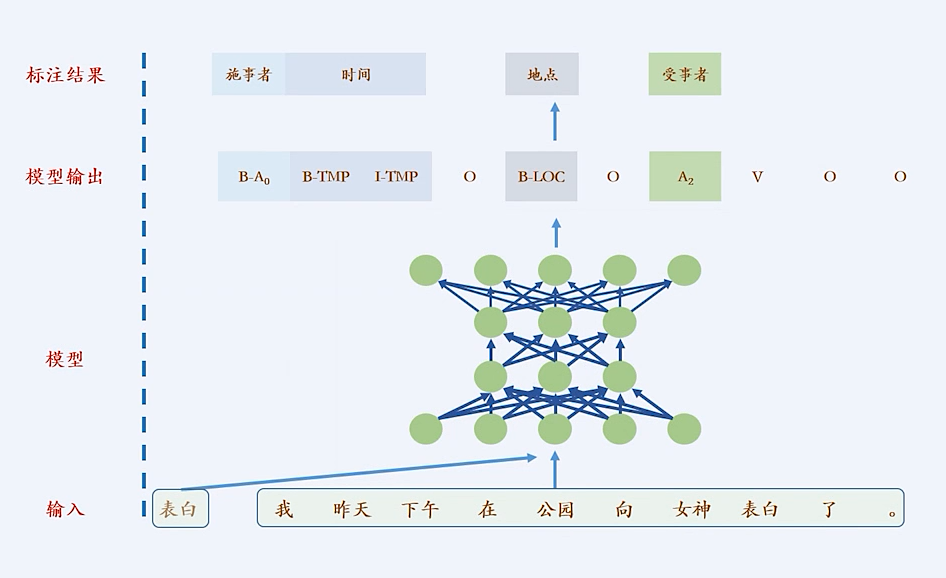
语义角色标注
语义角色标注是实现浅层语义分析的一种方式
谓词: 对主语的陈述或说明, 通常是一个动词
论元: 跟谓词搭配的名词
语义角色: 论元在动词所指事件中担任的角色

通过让计算机提取出重要的结构化信息,来"理解"语言的含义。
传统角色标注方法
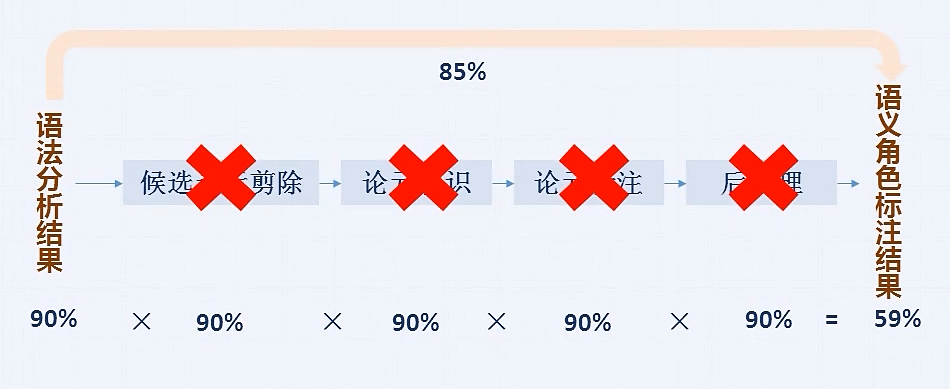
缺陷
高度依赖句法分析-------->只利用文本输入
每个步骤的错误会累积--------->端到端学习序列标注结果
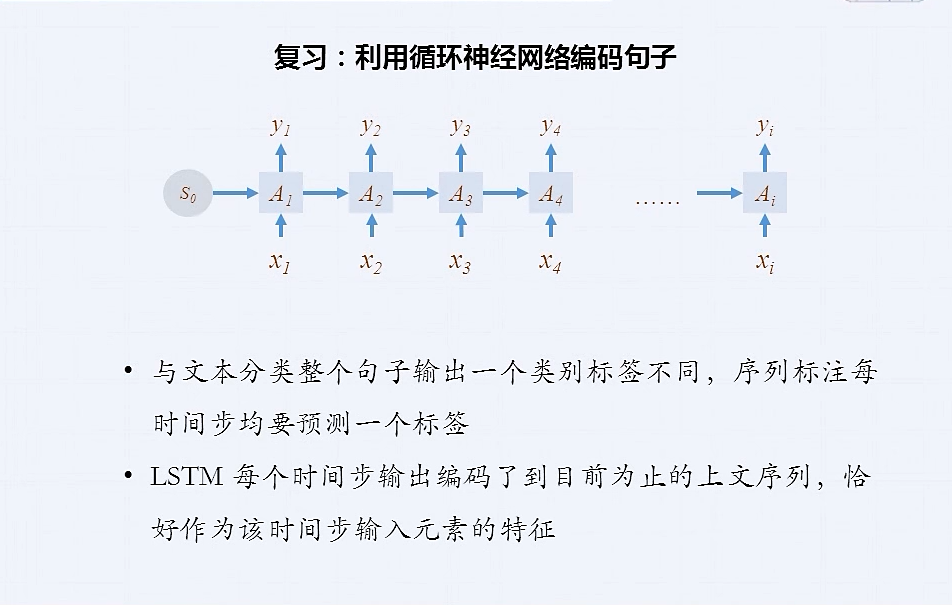

总结
栈式双向 LSTM 学习句子表示
CRF层在特征基础上完成序列标注
序列标注还能做: 分词, 词性标注, 语义角色标注, 命名实体识别
机器翻译
两个变长序列之间的映射问题
端到端的神经网络机器翻译原理及相关模型
门控循环单元(GRU) 和双向 RNN
编码器-解码器框架(Encoder-Decoder)
注意力机制(Attention)
柱搜索算法(Beam Search)
机器翻译概念解释
源语言: 被翻译的语言
目标语言: 翻译后的语言
平行语料(parallel corpus): 一一对应的源/目标语言
定义: 用计算机来实现从源语言到目标语言的转换过程
训练过程: 用大量的平行语料,来训练模型
生成过程: 根据预先训练的模型来翻译源语言句子
基于规则的翻译系统(早期)
转换规则: 由语言学家编写, 再将其录入计算机
缺点: 对语言学家的要求非常高,几乎无法总结一门语言会用到的所有规则, 更何况两种以上的语言。
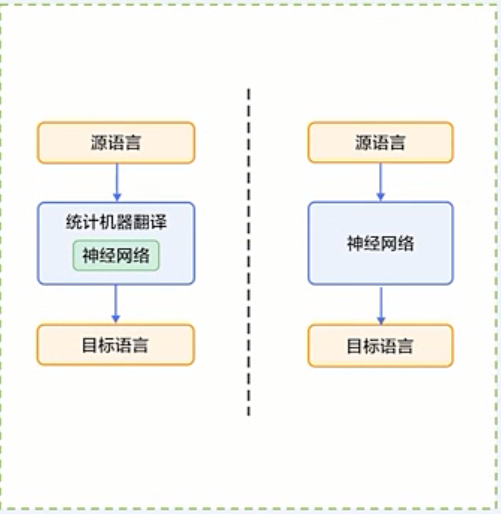
统计机器翻译(Statistical Machine Translation, SMT)
转换规则:
由机器从大规模语料中学习得到
缺点:
人为设计许多特征,但是永远无法覆盖所有语言现象
难以利用全局的特征
依赖许多预处理环节, 如词语对齐、分词或符号化等
每个环节的错误会逐步累积, 对最终翻译影响也越来越多
深度学习技术(端到端的神经网络机器翻译)
End-to-End Neural Machine Translation, 简称 NMT
1. 利用神经网络来改进其中的关键模块
2. 直接用神经网络将源语言映射到目标语言
序列到序列的学习问题
主要思想(2014年)
"Sequence to Sequence Learning with Neural Networks"
"Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation"
应用场景
文本到文本: 如智能机器人,文本摘要,绘画建模
图像到文本: 如看图说话,图片问答,图片搜索
文本到图像: 如基于文本描述生成一张图片
视频到文本: 如看视频说话, 视频搜索(视频 ------> 一句话或多句话)
LSTM 回顾(详见情感分析课程)
LSTM特点: 记忆单元、输入门、遗忘门及输出门
好处: 大大提升了 RNN 处理远距离依赖问题的能力
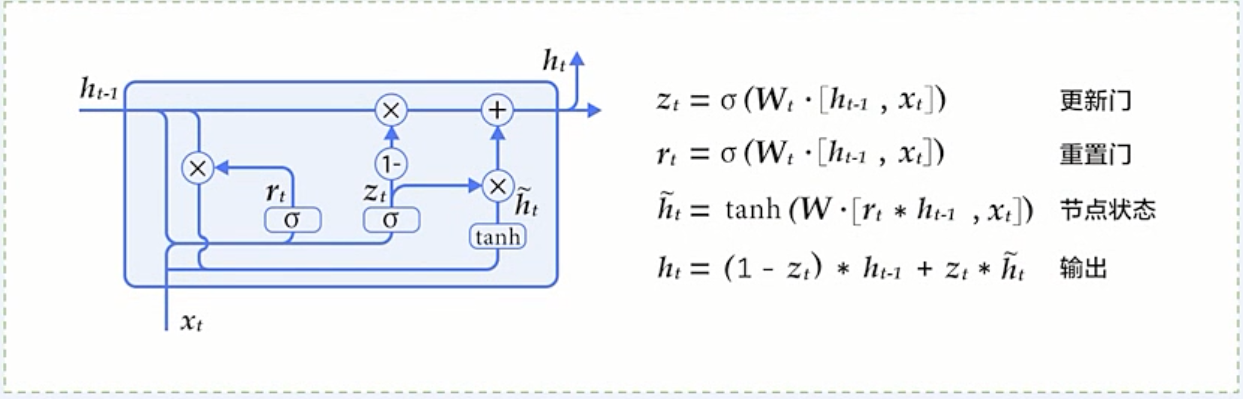
GRU 介绍
LSTM的简化版本, 只有两个门: 重置门和更新门
在多个任务上都和LSTM有相近的表现
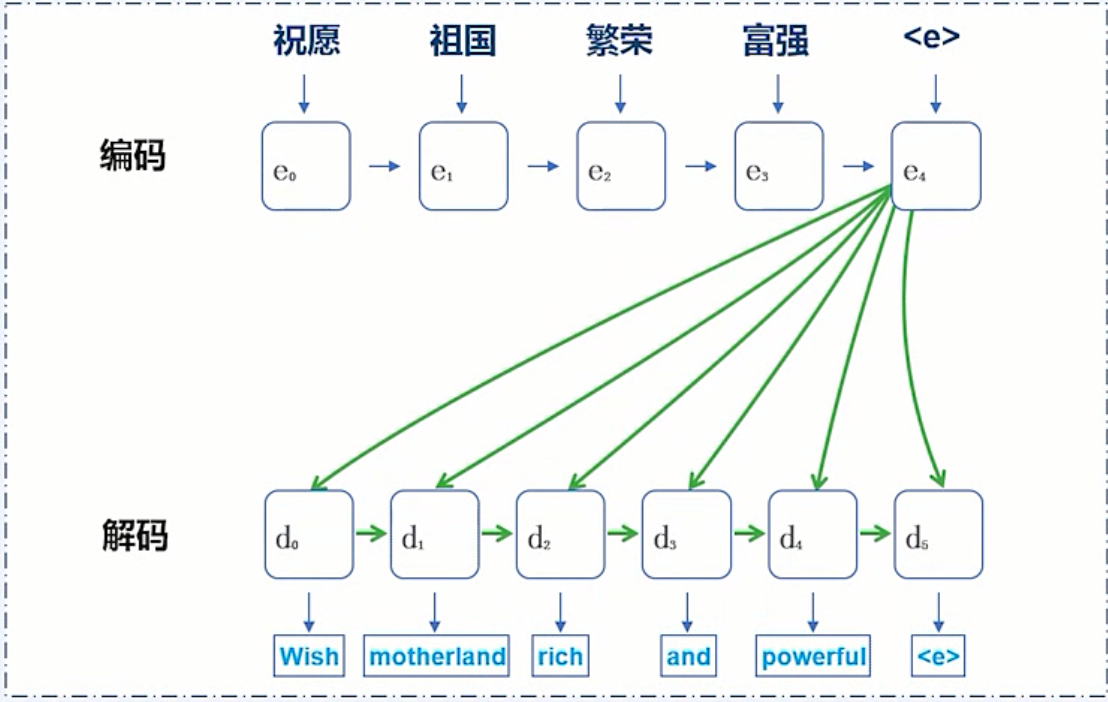
编码-解码器框架

编码:
将整个源序列表征成一个向量
解码:
通过最大化预测序列概率, 从中解码出整个目标序列
解码思路
计算下一个隐层状态
根据隐层状态得到词概率
根据词概率计算代价(训练)或采样出单词(生成)
循环以上三个步骤
训练: 直到目标语言序列中的所有词处理完毕
生成: 直到获得句子结束标记<e>或超过句子的最大生成长度
数据集
WMT14 数据集
