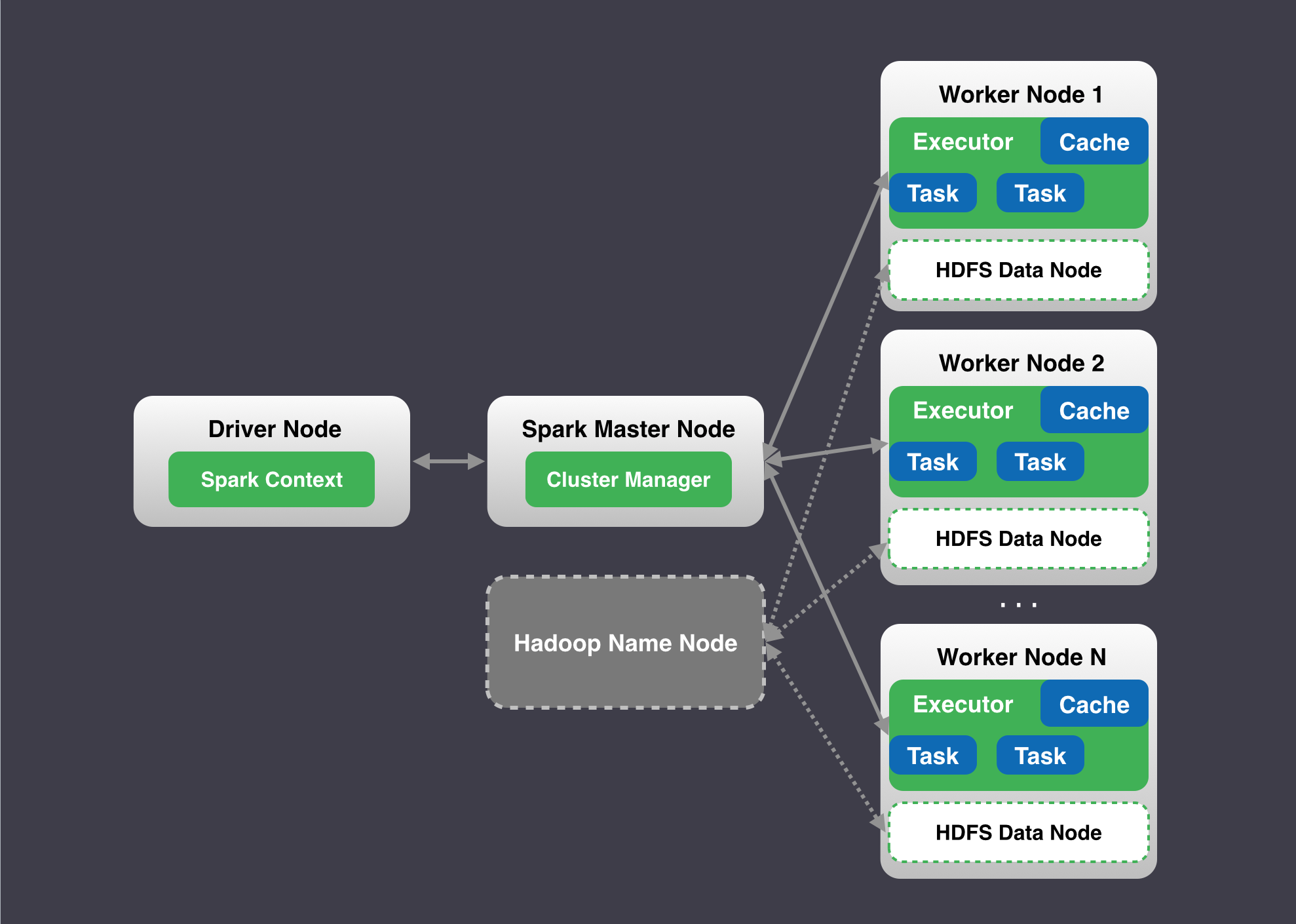
Spark 采用的是 master/slave 架构。Spark 可以运行在yarn mesos 等资源管理框架之上, 也可以以 Standalone cluster manager 进行集群资源管理。
Spark 依赖 Hadoop HDFS 作为数据存储。如果是纯计算集群,可以不依赖Hadoop。Spark本身的启动运行是不依赖Hadoop的。
Spark集群可以以下方式运行:
[quote]
主节点 (Spark master node 和 Hadoop NameNode)
从节点 (Spark worker nodes 和 Hadoop DataNodes)
客户端 (Driver node)
[/quote]
用户的 driver program 运行在 driver node上。
以下是Spark 架构图:
以 ubuntu 为例:[code]root@qianrushi:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# cat /etc/issue
Ubuntu 14.04.4 LTS \n \l[/code]
首先我们需要配置主机名称,这需要配置两个文件:
[quote]
/etc/hosts
[/quote]
[quote]
/etc/hostname
[/quote]
[code]root@qianrushi:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# cat /etc/hostname
qianrushi
root@qianrushi:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# cat /etc/hosts
#127.0.0.1 localhost
192.168.200.111 localhost
192.168.200.111 qianrushi
#127.0.1.1 localhost.localdomain localhost
192.168.200.111 localhost.localdomain localhost[/code] [code]root@ubuntu-server:~# tail -n 10 /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_91
export JRE_HOME=JAVA_HOME/lib/dt.jar:JAVA_HOME/bin:$PATH
export SCALA_HOME=/usr/local/scala
export PATH=SCALA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export PATH=HADOOP_HOME/bin
[/code][code]//----------------------------------------------------------------
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ubuntu-server:9011/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/tmp</value>
</property>
</configuration>
//----------------------------------------------------------------
hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_91
//----------------------------------------------------------------
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ubuntu-server:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
将Hadoop.tmp.dir所指定的目录删除。
重新执行命令:hadoop namenode -format
只有namenode需要format,secondarynamenode和datanode不需要format。
[/code]
可以通过spark-shell做简单测试:
[quote]
SPARK_EXECUTOR_MEMORY 的大小不能超过节点可用内存
[/quote]
[code]SPARK_EXECUTOR_MEMORY=2g ./bin/spark-shell --master spark://master:7077[/code]
测试1:[code]scala>val data = new ArrayInt
scala>for (i <- 0 until data.length)
| data(i) = i + 1
scala>val distData = sc.parallelize(data)
scala>distData.reduce(+)[/code]
测试2:
先将文件传到hdfs上:[code]root@qianrushi:~# cat test.txt
a
b
c
d
root@qianrushi:~# hdfs dfs -ls /
root@qianrushi:~# hdfs dfs -put test.txt /[/code]
进入sparks-shell:[code]scala>val textFile = sc.textFile("hdfs://master:9000/test.txt")
scala>textFile.filter(line => line.contains("a")).count()[/code]
spark官方文档测试 sparksql:[code]scala>val sqlContext = new org.apache.spark.sql.SQLContext(sc)
scala>val df = sqlContext.read.json("examples/src/main/resources/people.json")
scala>df.show()
scala>df.printSchema()
scala>df.select("name").show()[/code]
默认端口:
[quote]
Hadoop NameNode 50070 http://<Hadoop NameNode private IP>:50070
Spark master 8080 http://<spark master private IP>:8080
[/quote]
cankao:
[quote]
http://www.cnblogs.com/ringwang/p/3623149.html
http://hsrong.iteye.com/blog/1374734
http://www.ubuntukylin.com/ukylin/forum.php?mod=viewthread&tid=4702
http://blog.csdn.net/yeruby/article/details/21542465
[/quote]

